一致性是指多副本中的数据一致性问题,可以分为强一致性,顺序一致性,弱一致性
强一致性
在任意时刻,所有节点中的数据是一样的,例如,例如主从数据库,主库更新一个数据后,可以从从库读取到
可以指定复制所有库,指定库,或者指定表
主从复制的优点
- 主库负责写,从库负责读,可以分配负载以提高性能
- 数据备份,从库可以作为备份数据库
主从复制原理
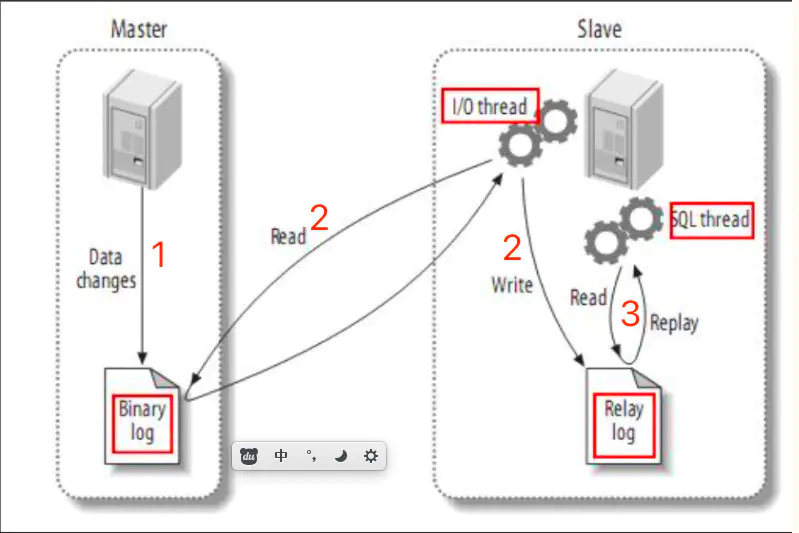
- 主库开启二进制日志
- 主库将sql语句通过
io线程保存在二进制日志binary log - 从库启动
io线程,读取主库的binary log到自己的中继日志realy log - 从库开启
sql线程,定时检查realy log,然后执行realy log语句 - 从库会记录主库二级制日志的坐标,所以从库可以暂停恢复继续处理
docker启动mysql容器
https://www.cnblogs.com/sablier/p/11605606.html
1 | # 镜像为mysql:5.7 |
主库配置
创建用户
1 | # 创建用于复制数据的用户,并只赋予replication权限 |
配置my.cnf
1 | # docker默认路径`/etc/mysql/my.cnf` |
- server-id 为0时,表示主库拒绝任何来自从库的连接
- 主从库server-id不能冲突,主要Master要依靠server_id来决定是否执行event。从库会把主库的event发送回主库???
- 多个从库的server-id不能冲突,server-id用来表示从库连接
从库配置
配置my.cnf
1 | [mysqld] |
测试sql
1 | # 创建users表 |
复制过程
当master上写操作繁忙时,当前POS点例如是10,而slave上IO_THREAD线程接收过来的是3,此时master宕机,会造成相差7个点未传送到slave上而数据丢失
- 异步复制
- 半同步复制
常见的错误
sql_slave_skip_counter表示跳过复制错误
- master上删除一条记录,而slave上找不到
set global sql_slave_skip_counter=1;
- 主键重复。在slave已经有该记录,又在master上插入了同一条记录
- 删除从库重复的记录
- 在master上更新一条记录,而slave上找不到,丢失了数据
- 从库补充数据,跳过
set global sql_slave_skip_counter=1;
- 从库补充数据,跳过
恢复relay-log日志
从库有两个线程,一个是Slave_IO_Running,一个是Slave_SQL_Running
Slave_IO_Running :接收master的binlog信息
- Master_Log_File
- Read_Master_Log_Pos
Slave_SQL_Running:执行写操作
- Relay_Master_Log_File
- Exec_Master_Log_Pos
1
2
3
4
5stop slave;
# MASTER_LOG_FILE对应Relay_Master_Log_File,MASTER_LOG_POS对应Exec_Master_Log_Pos
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=1609;
start slave;
show slave status\G;
mysql自定义dock镜像
1 | FROM mysql:5.7 |
主从复制需要考虑哪些问题?
主从复制延迟
主从复制有哪些方式?
- 半同步复制;防止主库挂掉后数据丢失(半同步复制确保事务提交后binlog至少传输到一个从库,只是传输到从库,不保证从库应用完这个事务的binlog )
- 并行复制;主要解决主从复制延迟问题
如何查看主从延迟的时间?
通过在从库执行命令show status,其中Seconds_Behind_Master可以反映延迟时间

