索引的本质是便于快速查找的数据结构,MySQL 数据库索引一般采用 B+Tree 作为索引的实现。
一、磁盘 IO 与预读
上面也讲了索引的目的是为了快速查找,MySQL 的数据存储在磁盘上,快速查找意味着降低磁盘的 I/O 次数。
磁盘 IO 是非常高昂的操作,计算机操作系统做了一些优化,当一次 IO 时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次 IO 读取的数据我们称之为一页 (page)。具体一页有多大数据跟操作系统有关,一般为 4k 或 8k,也就是我们读取一页内的数据时候,实际上才发生了一次 IO。
磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在 5ms 以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘 7200 转,表示每分钟能转 7200 次,也就是说 1 秒钟能转 120 次,旋转延迟就是 1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘 IO 的时间约等于 5+4.17 = 9ms 左右,听起来还挺不错的,但要知道一台 500 -MIPS 的机器每秒可以执行 5 亿条指令,因为指令依靠的是电的性质,换句话说执行一次 IO 的时间可以执行 40 万条指令,数据库动辄十万百万乃至千万级数据,每次 9 毫秒的时间,显然是个灾难。
二、B+Tree
2.1 B+Tree 概述
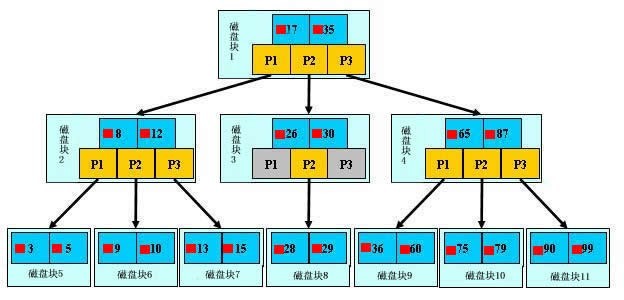
浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块 1 包含数据项 17 和 35,包含指针 P1、P2、P3,P1 表示小于 17 的磁盘块,P2 表示在 17 和 35 之间的磁盘块,P3 表示大于 35 的磁盘块。真实的数据存在于叶子节点即 3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如 17、35 并不真实存在于数据表中。
2.2 B+Tree 查找过程
如果要查找数据项 29,那么首先会把磁盘块 1 由磁盘加载到内存,此时发生一次 IO,在内存中用二分查找确定 29 在 17 和 35 之间,锁定磁盘块 1 的 P2 指针,内存时间因为非常短(相比磁盘的 IO)可以忽略不计,通过磁盘块 1 的 P2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存,发生第二次 IO,29 在 26 和 30 之间,锁定磁盘块 3 的 P2 指针,通过指针加载磁盘块 8 到内存,发生第三次 IO,同时内存中做二分查找找到 29,结束查询,总计三次 IO。真实的情况是,3 层的 b+树可以表示上百万的数据,如果上百万的数据查找只需要三次 IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次 IO,那么总共需要百万次的 IO,显然成本非常非常高。
2.3 B+Tree 性质
- IO 次数取决于 b+ 树的高度 h,假设当前数据表的数据为 N,每个磁盘块的数据项的数量是 m,则有 h=㏒(m+1)N,当数据量 N 一定的情况下,m 越大,h 越小;而 m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如 int 占 4 字节,要比 bigint8 字节少一半。这也是为什么 b+ 树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于 1 时将会退化成线性表。
- 当 b+ 树的数据项是复合的数据结构,比如 (name,age,sex) 的时候,b+ 数是按照从左到右的顺序来建立搜索树的,比如当 (张三,20,F) 这样的数据来检索的时候,b+树会优先比较 name 来确定下一步的所搜方向,如果 name 相同再依次比较 age 和 sex,最后得到检索的数据;但当 (20,F) 这样的没有 name 的数据来的时候,b+ 树就不知道下一步该查哪个节点,因为建立搜索树的时候 name 就是第一个比较因子,必须要先根据 name 来搜索才能知道下一步去哪里查询。比如当 (张三,F) 这样的数据来检索时,b+ 树可以用 name 来指定搜索方向,但下一个字段 age 的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是 F 的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
2.4 B+Tree 与 B-Tree 的区别
B+ 树只有叶节点存放数据,其余节点用来索引,而 B- 树是每个索引节点都会有 Data 域。为什么 MySQL 索引使用 B+Tree 而不使用 B-Tree 呢?其实在上面已经讲过了,B-Tree 因为节点存放数据会导致磁盘快的数据项变少,导致树的高度变高,查找时会增加 I/O 的次数。
三、索引优化
3.1 优化策略
- 最佳左前缀原则:当我们创建了的索引包括多列,查询的顺序应该是从索引的最前端开始,并且不要跳过索引中的其他列(跳过只会使用索引的一部分),如果最左端的字段不包括,索引直接失效
- 不要在索引列上做计算,函数等操作
- 不要在索引上做范围操作
- 在查询时尽量覆盖索引列,少使用
SELECT * - 不要在索引上使用 != 、 <> 、 IS NULL 、 IS NOT NULL
- 少使用 OR…
3.2 SQL 语句分析
如何判定一个 SQL 使用了索引,并评判它的性能,关于这点我们可以使用 EXPLAIN 关键字进行分析。以下是几个关于索引的重要字段:
- rows:根据表统计信息及选取索引的情况,大致估算出查到记录所需要读取的行数,所以优化语句基本上都是在优化rows
- type:表示查询语句的连接类型,该字段有很多值,最好到最差的顺序是:system > const > eq_ref > ref > range > index > all ,但是对于一般来说,能够保证达到 range 级别就可以了,最好达到 ref 级别
- key:实际上使用的索引,可以为 null 表示没有使用索引
参考
[1] MySQL索引原理及慢查询优化 by 美团技术团队 NeverMore
[2] MySQL索引背后的数据结构及算法原理 by 张洋

